
revlis.nl
Blog & Notes about OSS, OSes, devops, virtualization, programming (hobby) projects, security and tech news
July 12, 2024 — 19:41
Author: silver Category: dev Comments: Off
Building packages for 3rd party code with CI/CD in GitHub or GitLab.
Besides building application packages, you might want to create your own (custom) OS packages – for example in rpm or deb format. Which can then be tested and deployed. Using GitHub Actions or GitLab’s CI & API, creating packages can easily be automated. And that’s what this post is about.
First make sure we get source code. GitLab supports Repository mirroring and GitHub has a checkout action and several actions available in Marketplace that fully mirror repos. Also if there is no method yet to build the code and create a package, we need to create our own build script (in a new branch). Now a build job can run, either on a runner or using build image and container.
GitHub
Add job to workflow to get build artifacts and create release using ‘gh’ cli tool
Example:
jobs:
# ...
create-release:
name: Get artifacts and create release
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Download artifacts
uses: actions/download-artifact@v4
with:
path: build-artifacts
- name: Create release using 'gh'
run: |
gh release create mypkg-v$(date +%Y%m%d) $(find -type f -printf '%p ') --notes "my release notes"
working-directory: ./build-artifacts
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
GitLab
Ensure build artifacts are stored earlier in your pipeline and add a job that uploads and publish to package registry
Example:
# ...
build_job:
stage: build
#...
artifacts:
name: my-build-artifacts
paths:
- "build/example*"
publish_job:
stage: publish
dependencies: build_job
script:
- '/usr/bin/curl --silent
--header "JOB-TOKEN: $CI_JOB_TOKEN"
--upload-file "$FILE_NAME"
"https://instance-or-gitlab.com/projects/${CI_PROJECT_ID}/packages/generic/my_pkg/$(date +%Y%m%d)/${FILE_NAME}?status=default"
grep -q "201 Created" || exit 1'
For “versioning” we’ve simply used the current date, this probably should be a git tag or extracted from source. The next steps are adding a job to test the package and to deploy it (push). To be able to pull instead, you could set up your own repository. You could also consider using SaaS like packagecloud.io, artifactory or Ubuntu’s PPA to distribute the package.
October 27, 2023 — 17:16
Xpath or “XML Path Language” is for querying XML and can also be used on HTML DOM. Like selecting ‘div’ elements with a specific class. This can be used when scraping webpages, e.g. with Selenium or Playwright. It works similar to CSS selectors.
Syntax and examples below are all xpath 1.0 since this version is always supported by tools and libs. Version 2.0 adds more types, functions and operators (there’s also 3.0 and 3.1).
Syntax
child::(or'/') selects child (immediate)descendant::selects children (recursive)descendant-or-self::(or'//')@selects attributetext()selects element text
Examples
Select div with ‘myclass’ and ‘title’ attribute
html: <div class="myclass" title="My Title>
xpath: //div[@class="myclass"]/@title
returns: ‘My Title’
Select link with #my_id and then text
html: ‘<a id="my_id">foo bar</a>’
xpath //a[@id="my_id"]/descendant::text()
returns: ‘foo bar’
Testing
Queries can be tested from CLI with ‘xmllint’ (apt install libxml2-utils)
# html file:
xmllint --html --xpath '//a[@class="Results"]/@title' example.html
# actual xml, from curl:
curl http://restapi.adequateshop.com/api/Traveler?page=1 | \
xmllint --xpath '/TravelerinformationResponse/travelers/Travelerinformation/name -
More info
May 7, 2022 — 20:36
There’s a lot of things to like about GitLab in my opinion such as it’s API’s, the MR workflow and Terraform integration to name a few. Of course, there’s things to dislike too ;-)
Below are a few tips and notes on working with CI and editing .gitlab-ci.yml.
For a proper quick start see: https://docs.gitlab.com/ee/ci/quick_start
.
Variables
Predefined vars:
- Package Registry:
$CI_REGISTRY(docker login) - Docker image:
$CI_REGISTRY_IMAGE - Build dir:
$CI_PROJECT_DIR(docker WORKDIR) - Debugging:
$CI_DEBUG_TRACE: "true"
Full list: https://docs.gitlab.com/ee/ci/variables/predefined_variables.html
Conditional var:
Example where if INSTALL_ALL is set to "false", a docker image tag is added:
variables:
INSTALL_ALL = "true"
DOCKER_IMAGE: "${CI_REGISTRY_IMAGE}/foo"
workflow:
rules:
- if: $INSTALL_ALL == "false"
variables:
DOCKER_IMAGE: "${CI_REGISTRY_IMAGE}/foo:slim"
.
Jobs
Besides using the debug var mentioned above, this kludge is also useful when debugging. To quickly disable a job add a dot in front of it’s name “my_build_job”:
stages:
- test
- build
test_job:
stage: test
< ... >
.my_build_job:
stage: build
< ... >
.
Scripts
This is one line:
script:
- test -d dir &&
echo "dir exists"
Multi line:
script:
- |
echo "One"
echo "Two"
.
Tags
First add tag(s) to runner in GitLab GUI: ‘Settings > CI/CD > Runners’. Then use those tags in gitlab-ci.yml to select a specific runner for job execution.
E.g. add inside job:
tags:
- docker
- socket
.
Docker in Docker (dind)
Used to build containers. For own self-hosted Runners there’s 2 possible methods using the docker executer: "privileged" or "socket".
This requires changing config.toml, under [runners.docker]:
Add "/var/run/docker.sock:/var/run/docker.sock" to volumes
Or privileged = true
The socket method is more secure but can be a bit more difficult to work with. For example when you need access to $CI_PROJECT_DIR inside container. A solution is available here.
It’s also possible to use the shell executor (also allows using docker compose).
Other alternatives are using Podman/Buildah or Kaniko instead of Docker.
For details see https://docs.gitlab.com/ee/ci/docker/using_docker_build.html#enable-docker-commands-in-your-cicd-jobs.
May 5, 2022 — 18:00
What is a Man DevOps?
It started out with a pretty clear definition: Development and Operations teams working together (history at Wikipedia). Meaning Dev’s no longer throw code over the fence for Ops to take care of. And no more long waits for Ops to deliver new environments. Instead, leverage Infrastructure as Code (IaC) and create CI/CD pipelines to build, test and deploy code automatically.
Then it became a hype and now many companies use the name “DevOps Engineer” for all kinds of different roles such as Sysadmins or Platform/Infra Engineers. Since there is certainly overlap this can make matching knowledge, experience and skills to what is actually needed somewhat difficult.
Also, the term is currently often associated with Cloud, Microservices, Containers, Kubernetes, GitOps, services like AWS CF and Azure Pipelines and tooling such as GitLab CI, Docker, Ansible and Terraform…
and a lot more (via: CNCF, digital.ai)
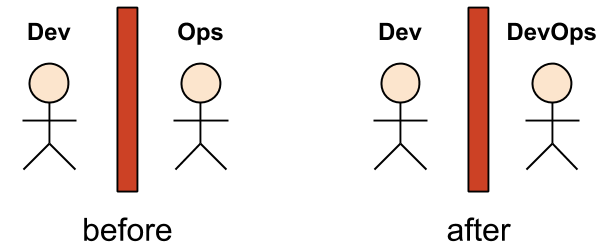
From source
DevOps ..without Devs? Wait, did anything actually change?

From source
…at least it’s easier to transfer a container to a cloud, than move a laptop to a DC ;)
July 16, 2021 — 16:31
Author: silver Category: dev Comments: Off
Some people still like to use a basic editor without linting, formatters or even syntax coloring. "Why do I need this and spent time setting it up?", they say.
I used to be one of those people, until I realized I was wasting time finding out I missed a curly brace or white space character somewhere, indentation was wrong or I used a variable out of scope. It’s simply a more efficient and pleasant workflow to just get a notice about such trivialities or get them fixed automatically. And with a bit more effort your editor can be an transformed into an IDE with code completion and (remote) debugging capabilities.
For example both Vim (vim-linting) and VSCode (awesome-vscode) can easily be extended with plugins for all kinds of specific programming languages from Python, Bash script or JS to C. And the same goes for config like Dockerfiles, JSON, YAML etc. But also think XML, HTML or Markdown.
Since we have CI/CD pipelines that take care of this too, does a local editor setup matter? Yes, because pipelines will fail on commit, you have to find out why and then make changes and retry. Why waste time?
Give your editor the love it deserves :)
October 30, 2020 — 16:31
Author: silver Category: dev Comments: Off
I never disliked JavaScript much for simple web stuff, never especially liked it either tho :)
But the past few months I’ve been using NodeJS, mainly for a console based app. I must admit it’s not useless and hyped as I thought. I do try to keep away from needless dependencies from its package manager NPM. Also something to get used to is that Node (and js) works asynchronously so your code could be executed ‘out of order’.
node
Run your ‘app.js’ with /usr/bin/node app.js.
Node itself includes useful functions like for making http(s) requests (nodejs.org docs).
It does not have to a be webapp though, creating a cli or gui app is also possible.
Node package manager
NPM (npmjs.org) has the usual functions like ‘search’ and ‘install’ but also lists insecure, unused or deprecated pkgs.
package.json
Here you can name your package and define stop and start scripts.
node_modules
The dreaded modules ("libs") go in this sometimes huge directory, managed by npm. For example ‘fs’ is for filesystem/io functions.
To use/import a module, add to top of your app: const fs = require('fs')
Another interesting module is ‘pm2’, a process manager which can be used to manage running your app including logging and monitoring (pm2.keymetrics.io).
Variables
- Global scope:
var - Local:
let - Constant:
const
Output text to console:
let var1 = "World"
console.log('Hello', var1)
console.log(`Hello ${var1}`) // this is a 'template literal'
JSON
Of course it is ‘supported’ as well as can be, which is nice :)
var jObj = {
“Foo”: "bar",
"Another Key": "Value",
}
add property
jObj['first name'] = 'John'jObj.firstname = 'John'
convert
- string to obj:
JSON.parse(string) - stringify obj:
JSON.stringify(obj)
Functions
'func(args) { ... }'
Maybe unusual is that you can use functions with another function as argument.
Arrow notation:
function() {}becomes() => {}function(a) {}becomesa => {}
And there’s…
- callbacks
- promises
- async and wait (syntactic sugar over promises)
(in order from ‘old’ to ‘current’)
These pages helped me better understand these concepts:
April 3, 2020 — 12:31
Bash Automated Testing System
BATS is a framework for unit testing Bash scripts. The latest version can be found here: https://github.com/bats-core/bats-core
Testing will make sure changes to your script do not break stuff but you wont have to do this by hand every time, instead using BATS to automate it for you.
Bats test files have the ".bats" extension, and can be run like this: bats example.bats.
Libraries
There’s two extra repos you’ll also want to check out and load at the start of your tests:
Example
An example test case might look like this:
#!/usr/bin/env bats
load 'bats-support/load'
load 'bats-assert-1/load'
@test "$(date '+%H:%M:%S') test help" {
run your_script.sh -h
[ "$status" -eq 0 ]
assert_output --partial "USAGE:"
}
@test "$(date '+%H:%M:%S') test invalid argument" {
run your_script.sh -invalid
[ "$status" -eq 1 ]
assert_output --partial 'Error: invalid or unknown arg(s)'
}
We’ll first display the time and some text, then test the output "your_script.sh" by running it.
The first case will pass if your_script.sh -h outputs the text "USAGE:". There can also be other text output before and after since we assert a partial match.
The second case checks what the script would output on an invalid error and compares it to "Error: invalid or unknown arg(s)". If it’s the same, the test will pass.
More testing
If you need more complicated testing there’s also functions and variables. Two default functions are setup() and teardown() to set tests up.
A good way to run tests is to be able to call the functions inside your script directly, so you probably want to consider this beforehand.
Alternatively there’s also other frameworks available:
February 14, 2020 — 14:49
Besides Chocolatey there’s also https://scoop.sh. A more "dev" oriented package manager for Windows PowerShell.
It installs "UNIXy" packages such as Git, cURL and vim. Languages such as Perl, PHP Python and Go are available just like Apache, Nginx and MySQL. Packages are installed into your homedir/profile, no UAC needed or changing PATH env var.
July 9, 2019 — 9:17
I’ve been using PS for a while now and I don’t hate it anymore :) In fact, I think it’s very usable for lots of tasks and automation. Easy to learn too, a bit like “python-lite” for sysadmins perhaps.
Here’s some Useful commands
discover/help:
Get-Command *help*orGet-Command-Module PackageManagementGet-Memberto view properties e.g.Get-Disk | Get-MemberGet-Alias
access:
Get-ExecutionPolicy -ListSet-ExecutionPolicy -ExecutionPolicy RemoteSigned- Run as admin:
powershell.exe -Command "Start-Process cmd -Verb RunAs"
support for csv, xml and json is included:
Import-CSVExport-CSVConvertTo-XMLConvertFrom-JsonConvertTo-Json
And stuff like:
- piping to
select,sortandwhere(grep) Invoke-WebRequest $url(curl)- Logging sessions:
Start-TranscriptStop-Transcript - Viewing Certificates:
cd Cert:\(now you can ‘dir’ etc) - PS Linting: https://github.com/PowerShell/PSScriptAnalyzer and Testing: https://pester.dev
Remote usage is also possible over WinRM (or OpenSSH):
Enter-PSSession -ComputerName <host>
Then there’s Loops, Params, Arrays and Hash Tables e.g. foreach, Param([string]$arg), @() and @{}…
Besides for Windows and Azure, PS (Core) can also be used on Linux/MacOS and then there’s PowerCLI for VMware. Not bad, not bad at all.
More info:
- https://learn.microsoft.com/en-us/shows/it-ops-talk/how-to-install-powershell-7
- https://docs.microsoft.com/en-us/powershell/scripting/install/installing-windows-powershell?view=powershell-6
- https://docs.microsoft.com/en-us/powershell/dsc/overview/overview
- https://github.com/powershell/powershell
- https://github.com/PowerShell/openssh-portable
May 30, 2019 — 20:50
Linting is basically making sure source code is correct.
For Vim there’s ALE: Asynchronous Lint Engine. It supports multiple tools like cpplint for C/C++, ShellCheck for shell scripts, phan for PHP etc etc.
Download
Get it here: https://github.com/w0rp/ale
Commands
- ALELint
- ALEEnable
- ALEDisable
- ALENext
- ALEPrevious
.vimrc
To use Ctrl+j and Ctrl+k to moving between errors:
nmap <silent> <C-k> <Plug>(ale_previous_wrap)
nmap <silent> <C-j> <Plug>(ale_next_wrap)
December 8, 2018 — 18:52
Author: silver Category: dev Comments: Off
IDE/Editor
- Eclipse (CDT)
- VS Code (MS C extensions)
- Vim
Formatting:
1TBS of course ;)
Setup vi manually:
set noai tabstop=8 shiftwidth=8 softtabstop=8 noexpandtab
or use modeline in file:
/* vim: set noai tabstop=8 shiftwidth=8 softtabstop=8 noexpandtab: */
Strings
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
char str[12] = "Hello World";
char str[0] = '\0';
char buf[];
copy: strcpy(str2, str1)
concat: strcat(str1, str2)
length: strlen(str)
duplicate: ptr = strdup(str)
substring: strstr(str1, str2)
extract: strsep(*strptr, delimstr)
strstr():
locate subscring
or: “check if ‘sent’ contains ‘word'”
if(strstr(sent, word) != NULL) //..or skip NULL check
strsep():
- extract token
- or: “split substring using delim”
- like deprecated strtok()
while((found = strsep(&string,",")) != NULL)
Things to remember
- set it before using it (initialize)
- strings are char arrays terminated by \0
- strings in double quotes are auto terminated by \0
- strcpy : watch out for buffer overruns with long strings
- use : checks,
char buf[1024], \0 term,malloc(strlen(str) + xx) - buf[] has no size and no space allocated
- convert int to string:
itoa,sprintf,snprintf(buf, 10, "%d", num);
tutorialspoint.com/cprogramming/c_strings.htm
printf outputs to stdout stream
fprintf goes to a file handle FILE*
sprintf goes to a buffer you allocated (char*)
printf("This is a str: %s\n", str);
fprintf(fh, "log: %s", str);
sprintf(buf, "%s %s", str1, str2);
int: %d
long int: %ld
long long int: %lld
unsigned long long int: %llu
“%s” format specifier for printf always expects a char* argument
Pointers
// ptr is going to store address of integer value
int i = 20;
int *ptr;
Operator Operator Name Purpose *ptr * Value at Operator gives Value stored at particular address type* ptr; Same Same &ptr & Address Operator gives Address of Variable **ptr Double Pointer declares a Pointer to a Pointer
- using *ptr is actually the first element (not its address)
- while
int *varis the same asint* var,*varis better/more clear to use - initialize (NULL or valid address)
Extern
- tell compiler variable is declared elsewhere
- use only in one place
example.h:
extern int global_variable;
example.c:
#include "example.h"
int global_variable = 1337;
example2.c:
#include "example.h"
void use_it(void)
{
printf("Global variable: %d\n", global_variable++);
}
Compiler messages
warning: implicit declaration of function 'function' [-Wimplicit-function-declaration]
You are using a function for which the compiler has not seen a declaration (“prototype”) yet.
int main()
{
fun(2, "21"); /* The compiler has not seen the declaration. */
return 0;
}
int fun(int x, char *p)
{
/* ... */
}
You need to declare your function before main, like this, either directly or in a header:
int fun(int x, char *p);
From stackoverflow.com/a/8440833
Macros
ifdef : “if defined” (quelle surprise;)
#ifndef : if NOT defined
example.c:
#ifdef DEBUG
printf("DEBUG: %s\n", dbgstuff);
#endif
gcc -DDEBUG -c
gcc.gnu.org/onlinedocs/cpp/Ifdef.html
Include guard
#ifndef : checks whether the given token has been #defined earlier in the file or in an included file; if not, it includes the code between it and the closing #else or, if no #else is present, #endif statement.
#ifndef : is often used to make header files idempotent by defining a token once the file has been included and checking that the token was not set at the top of that file.
example.h:
#ifndef _INCL_GUARD
#define _INCL_GUARD
#endif
cprogramming.com/reference/preprocessor/ifndef.html
Malloc
char *buf = (char *) malloc(bufferSize);
where bufferSize is the runtime result of some computation
Examples:
char *string = (char*)malloc(n+1 * sizeof(char));
size_t length = strlen(str1) + strlen(str2) + 1;
char *concat = malloc(sizeof(char) * length);
char* buffer = (char*)malloc(256);
rhost = (char *)malloc(sizeof(char)*128);
- if allocatable buffer space is variable, use malloc instead of buf[1024]
- when done use free: free(buf);
- strdupe already does malloc, no malloc needed
Execute command
exec() & friends like execve
system("ls -la")
get output: popen()
FILE *fp = popen("ls -la", "r");
if (fp)
fscanf(fp, "%100s", var);
-or-
fgets(var, 100, fp);
Return
return 0 or 1:
int function {
if (success) { return 0; }
return 1;
}
return char* value:
char* function {
char *buf;
...
return buf;
}
(use malloc or buf[1024] and free)
Examples:
str functions (example):
printf ("\nDEBUG: strncmp %s %i\n", flist_getfilename(ftmp), strncmp(flist_getfilename(ftmp), ".mp3", 4));
printf ("\nDEBUG: strcmp %s %i\n", flist_getfilename(ftmp), strcmp(flist_getfilename(ftmp), ".mp3"));
printf ("\nDEBUG: strcasecmp %s %d\n", flist_getfilename(ftmp), strcasecmp(flist_getfilename(ftmp), ".mp3"));
more strcmp:
if (!strncmp(flist_getfilename(ftmp), ".mp3", 4))
if (strncmp(flist_getfilename(ftmp), ".mp3", 4) != 4 )
March 30, 2018 — 14:26
Author: silver Category: dev Comments: Off
Print modules:
python3 -c "import sys;print (sys.path)"
python3 -c "import sys;print (sys.modules)"
python3 -c "help('modules')"
python3 -c "help('modules package')"
pydoc3 modules
Packages:
- Location in Debian: /usr/lib/python{3}/dist-packages/pkgname/{__init__.py}
- Other distro’s use “site-packages”
pip3 install pkgname
pip3 uninstall pkgname
pip3 freeze
python3 -m pip install pkgname
python3
import pip
sorted(["%s==%s" % (i.key, i.version) for i in pip.get_installed_distributions()])
Virtualenv:
$ pip3 install virtualenv
$ mkdir workdir && cd workdir
$ virtualenv project
$ source project/bin/activate
$ pip3 install requests
(and/or git clone + python3 setup.py install / etc)
$ deactivate
$ rm -rf project
Strings:
Besides %-format and str.format() there’s now also f-Strings (since Python 3.6).
Example:
foo="value"
print(f'This string has a variable: {foo}.')
Notes:
- make sure your script.py does not have the same name as package
- print syntax changed from python2 to 3:
print ("foo")
March 30, 2018 — 9:50
Author: silver Category: dev Comments: Off
List installed modules:
Pick one :)
perl -Vperldoc <module name>perldoc perllocalinstmodshcpan -[l,a]
or:
perl -e 'use ExtUtils::Installed; foreach (ExtUtils::Installed->new()->modules()) {print $_ . "\n";}'
Install modules in homedir:
- install “local::lib” module
- print settings:
perl -Mlocal::lib - add to .bashrc:
eval "$(perl -I$HOME/perl5/lib/perl5 -Mlocal::lib)"
Then there’s also “Perlbrew“.
You must be logged in to post a comment.